PMPP Chapter 1: Introduction

Traditionally (before 2003), microprocessors are based on single central processing unit (CPU), but due to energy consumption and heat dissipation issues that limited the clock frequency, single CPU’s performance improvement had been slowed.
Heterogeneous Parallel Computing
Two major trajectories have been settled for designing microprocessors:
- The multi-core trajectory seeks to maintain the execution speed of sequential programs while moving into multiple cores. Examples are modern CPUs with around 10 to 200 cores and are out-of-order, multiple instruction issue processor implementing the full X86 instruction set with hyper-threading support.
- In contrast, the many-thread trajectory focuses more on the execution throughput of parallel applications. A modern GPU like the NVIDIA H100 supports 10s of 1000s threads, executing in a large number of simple, in-order pipelines.
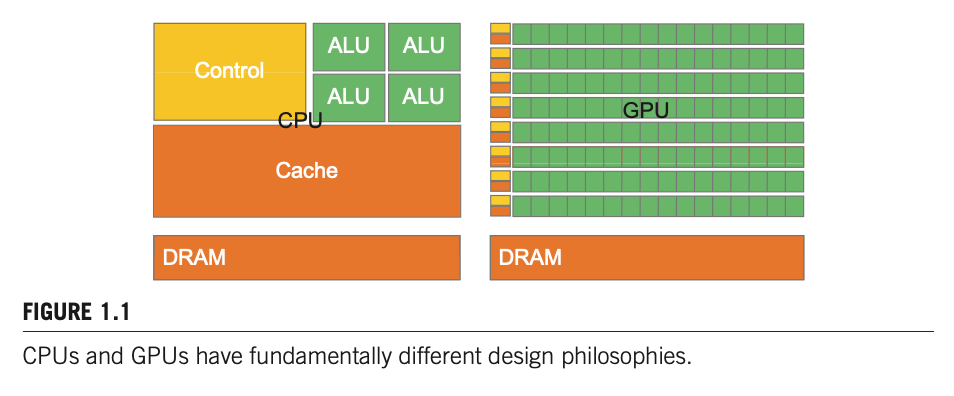
The two different trajectories for CPU and GPU are results of their different design goals:
- CPU’s design style is commonly referred to as latency-oriented design, aiming for optimizing sequential code performance and minimize the execution latency of a single thread. It makes use of sophisticated control logic to allow instructions from a single thread to execute in parallel or even out of the sequential order while maintaining the appearance of sequential execution.
- GPU’s design style, on the other hand, is referred to as throughput-oriented design as it strives to maximize the total execution throughput of a large number of threads while allowing individual threads to take a potentially much longer time to execute.
Modern GPU Architecture
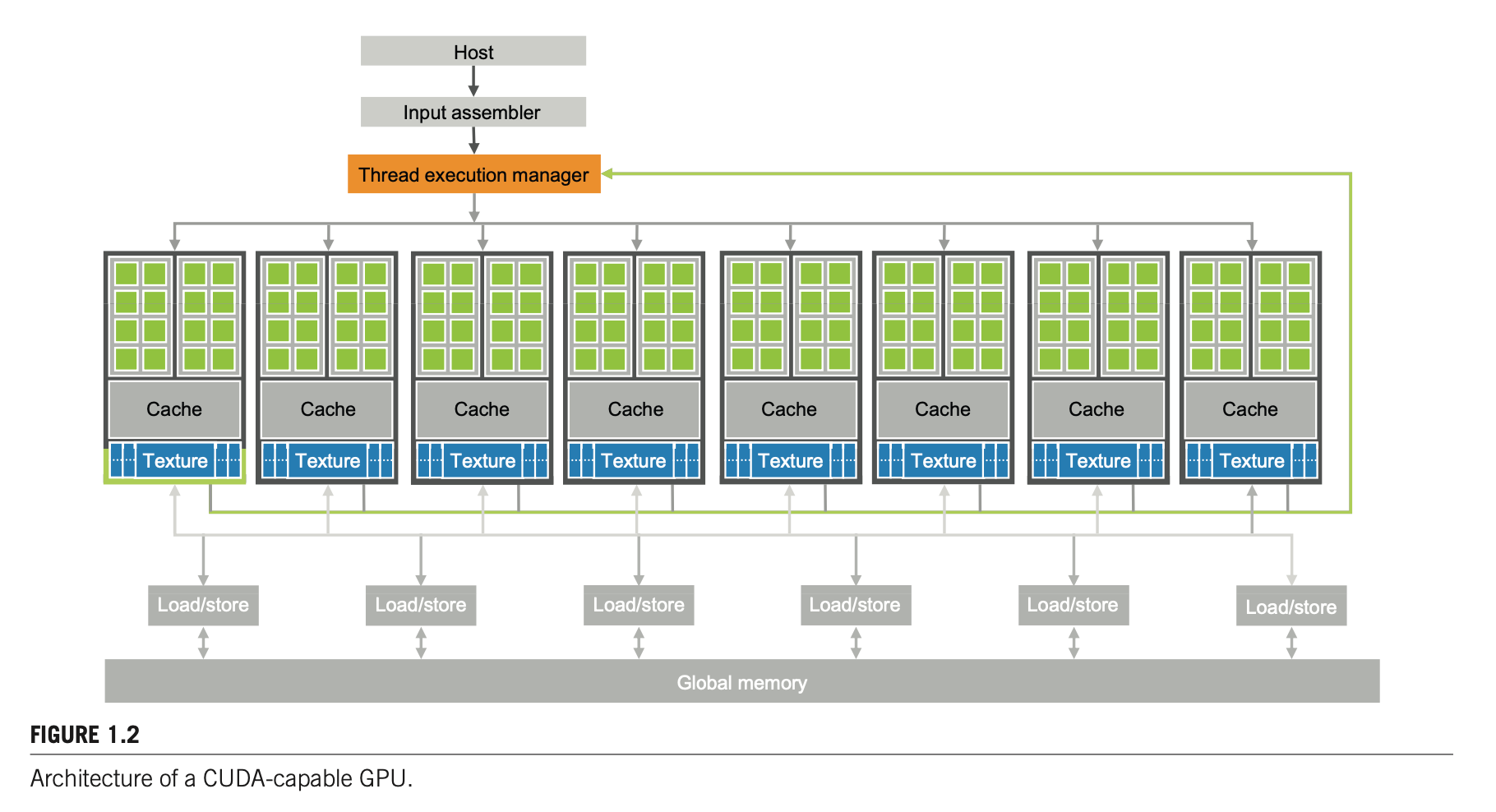
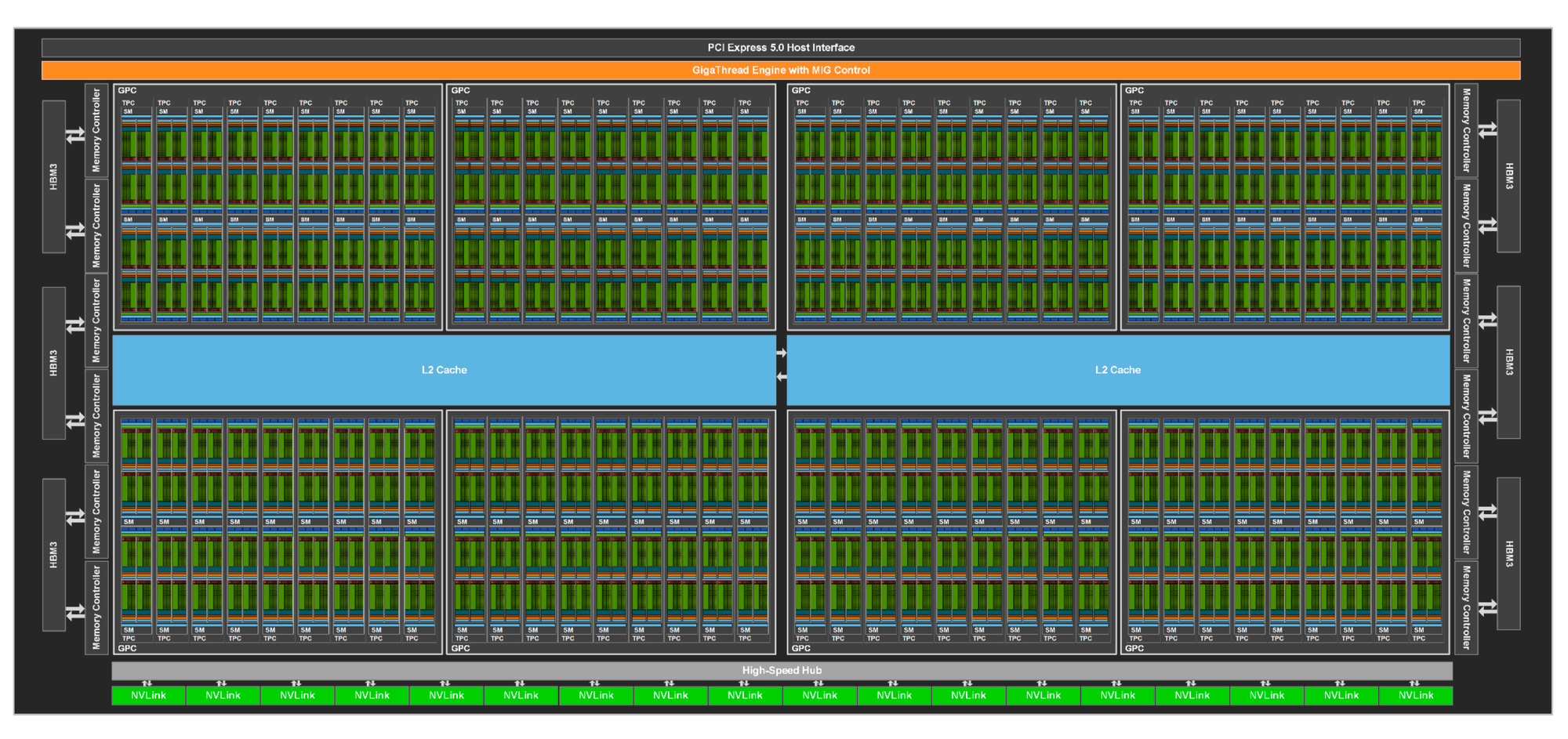
A modern GPU is organized into an array of highly threaded streaming multiprocessors (SMs), and each SM has a number of streaming processors (SPs) that share control logic and instruction cache. Each GPU currently comes with gigabytes of memory referred to as Global Memory.

Parallel Programming Languages and Models
Before CUDA release in 2007, graphics chips programming was very difficult as graphical APIs (e.g. OpenGL, Direct3D) were the only ways to access the processing unit. In other words, a computation must be expressed as rendering a pixel in order to execute on GPU.
CUDA provides a general-purpose parallel programming interface and has greatly expanded the types of applications that one can easily develop for GPU using C / C++.
Other than CUDA, two most commonly used parallel programming models are Message Passing Interface (MPI) for scalable cluster computing and OpenMP for shared memory multiprocessor systems.
- OpenMP works by specifying directives (commands) and pragmas (hints) about a loop to the OpenMP compiler, and when executing, the OpenMP runtime system supports the execution of the parallel code by managing parallel threads and resources.
- OpenMP was originally designed for CPU execution and adds support for offloading in a later version. A variation of OpenMP, OpenACC, have been designed for programming heterogeneous systems.
- MPI is a model where compute nodes in a cluster do not share memory. All data sharing and interaction must be done through explicit message passing.
- Joint CUDA/MPI programming is required for parallel programmer in HPC, with CUDA within each node, and MPI communication across the cluster.
Speeding Up Real Applications
The speed-up of a real-world application depends on the portion of the application that can be parallelized.
Most applications have portions that can be much better executed by the CPU. Thus, one must give the CPU a fair chance to perform and make sure that code is written so that GPUs complement CPU execution, thus properly exploiting the heterogeneous parallel computing capabilities of the combined CPU/GPU system.
Researchers have achieved speedups of more than 100X for some applications. However, this is typically achieved only after extensive optimization and tuning after the algorithms have been enhanced so that more than 99.9% of the application execution time is in parallel execution.
In practice, however, the straightforward parallelization of application often saturates the memory bandwidth, resulting only 10x speedup.
Challenges in Parallel Computing
- It can be challenging to design parallel algorithms with the same level of algorithmic (computational) complexity as sequential algorithms
- The execution speed of many applications is limited by memory access speed; those applications are known as memory-bounded, as opposed to compute-bounded.
- The execution speed of parallel programs is often more sensitive to the input data characteristics than their sequential counter parts.
- Many real-world problems are most naturally described with mathematical recurrences, which is non-intuitive to parallelize.
This is chapter 1 of my notes on Programming Massively Parallel Processors.