PMPP Chapter 2: Data Parallel Computing

Data Parallelism
When modern software applications run slowly, the problem is usually having too much data to be processed.
- Image or video manipulation application with millions to trillions of pixels
- Molecular dynamics applications simulating millions of atoms
Importantly, most of these pixels, particles, cells and so on can be dealt with largely independently.
Such independent evaluation is the basis of data-parallelism: (re)organize the computation around the data, such that we can execute the resulting independent computations in parallel to complete the overall job faster, often much faster.
Task Parallelism
Data parallelism is not the only type of parallelism used in parallel programming. Task parallelism has also been used extensively.
Task parallelism is typically exposed through task decomposition of applications. In large applications, there are usually a large number of independent tasks and therefore a large amount of task parallelism.
In general, data parallelism is the main source of scalability for parallel programs, but task parallelism can also play an important role in achieving performance goals.
CUDA C Program Structure
The structure of a CUDA C program reflects the coexistence of a host (CPU) and one or more devices (GPUs) in the computer. Each CUDA source file can have a mixture of both host and device code.
Compilation
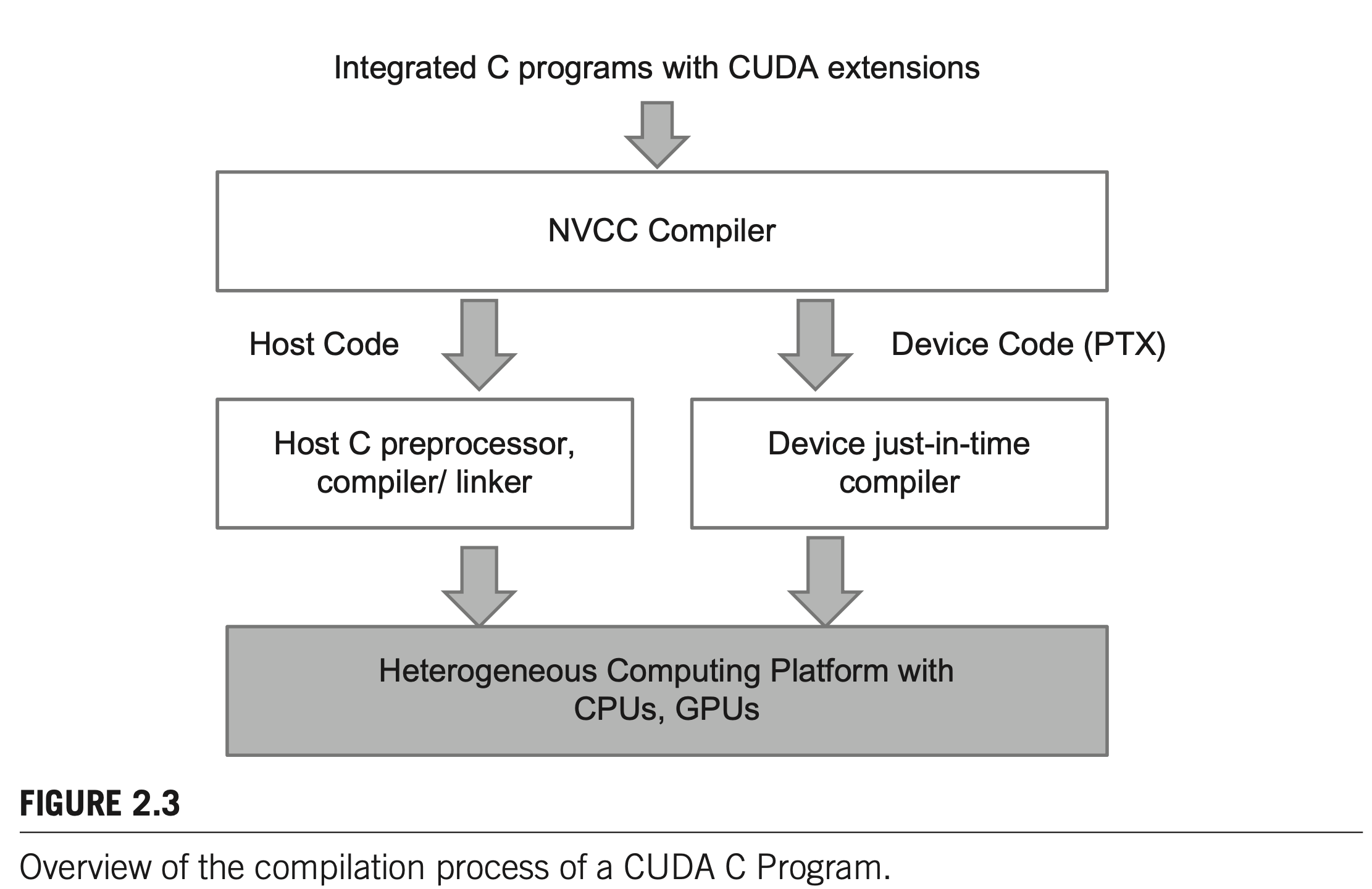
The NVCC (NVIDIA C Compiler) processes a CUDA C program, using the CUDA keywords to separate the host code and device code.
The host code is straight ANSI C code, which is further compiled with the host’s standard C/C++ compilers and is run as a traditional CPU process.
The device code is marked with CUDA keywords for data parallel functions, called kernels, and their associated helper functions and data structures. The device code is furthered compiled by a run-time component of NVCC and executed on a GPU device.
Execution
The execution starts with host code (CPU serial code). When a kernel function (parallel device code) is called, or launched, it is executed by a large number of threads on a device. All the threads that are generated by a kernel launch are collectively called a grid. These threads are the primary vehicle of parallel execution in a CUDA platform.
Launching a kernel typically generates a large number of threads to exploit data parallelism. But unlike traditional CPU threads that typically take thousands of clock cycles to generate and schedule, threads on CUDA only take very few clock cycles to generate and schedule due to efficient hardware support.
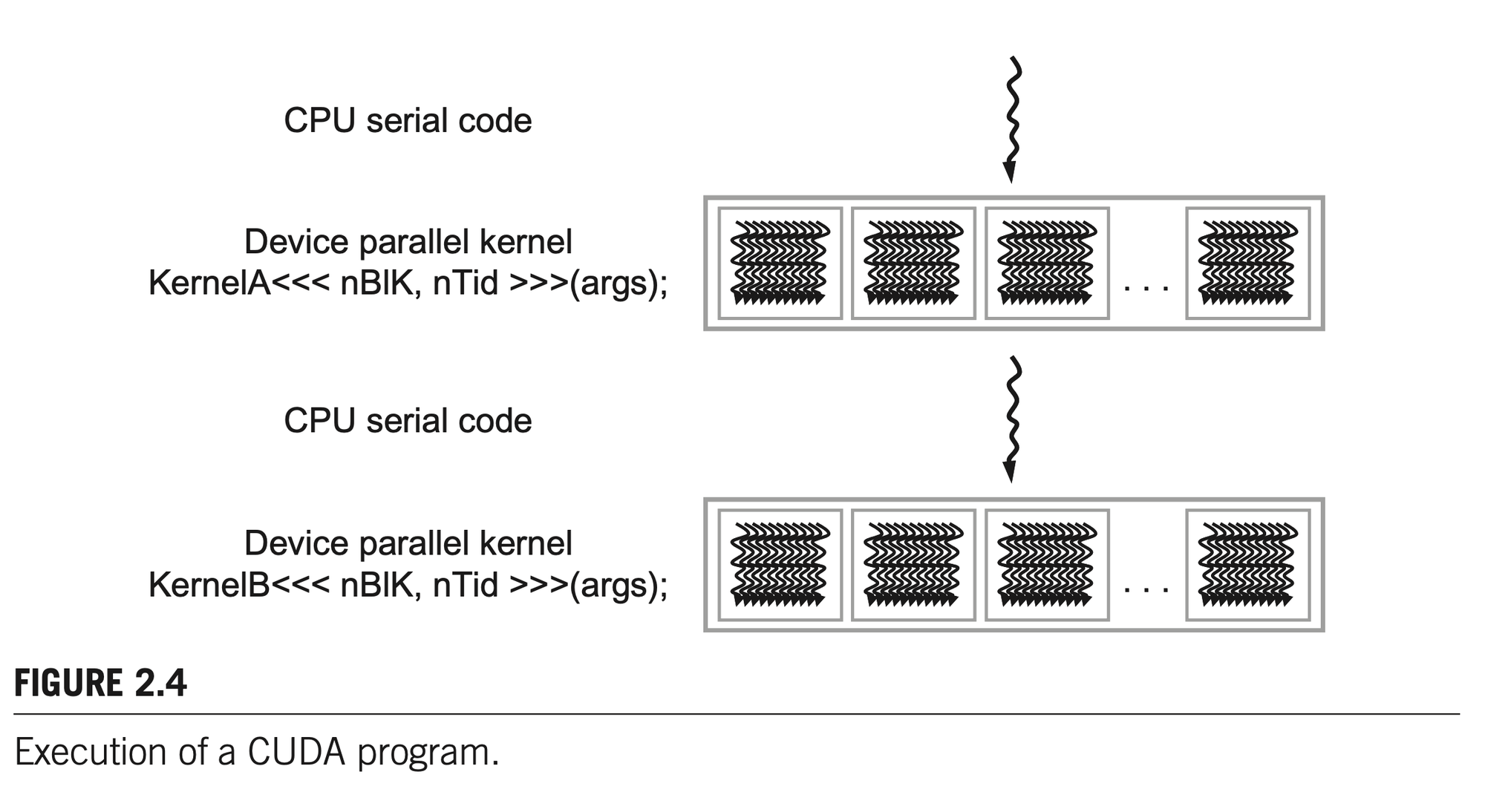
The execution of each thread is sequential, but threads may be executed in any arbitrary order depending on the run-time scheduler.
A Vector Addition Kernel
In order to execute a kernel on device, the programmer needs to allocate global memory on the device and transfer pertinent data from the host memory to device memory. Similarly, after device execution, the programmer need to transfer result data from the device memory back to the host memory and free up the device memory that is no longer needed.
void vecAdd(float* A, float* B, float* C) {
// 1. Allocate device memory for A, B and C
// Copy A and B to device memory
// 2. Kernel launch code
// 3. Copy C from device memory
// Free device vectors
}This function is essentially an outsourcing agent that ships input data to a device, activates the calculation on the device, and collects the results from the device.
Device Memory Allocation, Free and Transfer
cudaMalloc() , similar to malloc() in C for host memory, allocates object in the device global memory.
cudaFree() , similar to free() , frees object from device global memory.
cudaMemcpy(), similar to memcpy() , handles memory data transfer.
__host__ __device__ cudaError_t cudaMalloc ( void** devPtr, size_t size )
__host__ __device__ cudaError_t cudaFree ( void* devPtr )
__host__ cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind ) Error Checking
CUDA API functions return flags that indicate whether an error has occurred when they served the request.
cudaError_t err=cudaMalloc((void **) &d_A, size);
if (err !=cudaSuccess) {
printf(“%s in %s at line %d\n”, cudaGetErrorString(err),__FILE__,__LINE__);
exit(EXIT_FAILURE);
}Kernel Functions and Threading
In CUDA, a kernel function specifies the code to be executed by all threads during a parallel phase. This is known as Single-Program-Multiple-Data (SPMD) parallel programming style.
When a program’s host code launches a kernel, the CUDA run-time system generates a grid of threads that are organized into a two-level hierarchy. Each grid is organized as an array of thread blocks, which will be referred to as blocks for brevity. All blocks of a grid are of the same size; each block can contain up to 1024 threads.
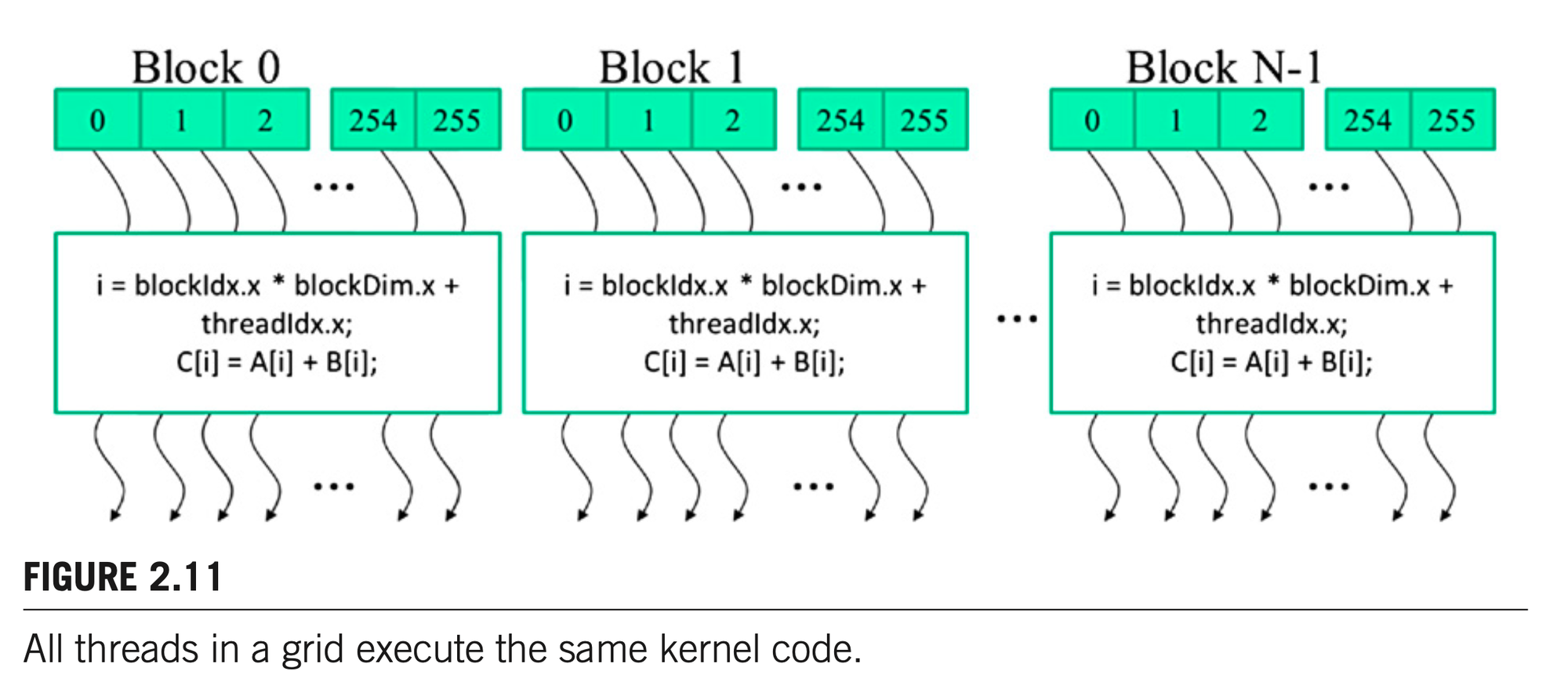
Each thread has its block ID and thread ID, which help to uniquely identify the thread. Thread Dimension is a struct type with x, y, z fields. The choice of dimensionality for organizing threads usually reflects the dimensionality of the data.
__global__
void vecAddKernel(float* A, float* B, float* C, int n)
{
int i = blockDim.x*blockIdx.x + threadIdx.x;
if(i<n) C[i] = A[i] + B[i];
}CUDA C extends the C language with three qualifier keywords that can be used in function declarations.

For automatic (local variable), like the integer i in the vector add example, it’s private to each thread and each thread owns a copy of that variable.
The kernel function does not have a explicit loop over the range, but the entire execution grid forms the equivalent of the loop. Each thread in the grid corresponds to one iteration of the original loop. This type of data parallelism is sometimes also referred to as loop parallelism.
Kernel Launch
int vectAdd(float* A, float* B, float* C, int n)
{
// d_A, d_B, d_C allocations and copies omitted
// Run ceil(n/256) blocks of 256 threads each
vecAddKernel<<<ceil(n/256.0), 256>>>(d_A, d_B, d_C, n);
}When the host code launches a kernel, it sets the grid and thread block dimensions via execution configuration parameters in <<< >>>.
This is chapter 2 of my notes on Programming Massively Parallel Processors.