PMPP Chapter 3: Scalable Parallel Execution

CUDA Thread Organization
All CUDA threads in a grid execute the same kernel function; they rely on coordinates to distinguish themselves from one another and identify the appropriate portion of data to process.
These threads are organized into a two-level hierarchy:
- a grid consists of one or more blocks;
- each block consists of one or more threads
In general, a grid is a three-dimensional array of blocks, and each block isa three-dimensional array of threads. Programmers can use fewer than three dimensions by setting the size of the unused dimensions to 1.
dim3 dimGrid(32, 1, 1)
dim3 dimBlock(128, 1, 1);
vecAddKernel<<<dimGrid, dimBlock>>>(...);
// equivalent
vecAddKernel<<<32, 128>>>(..);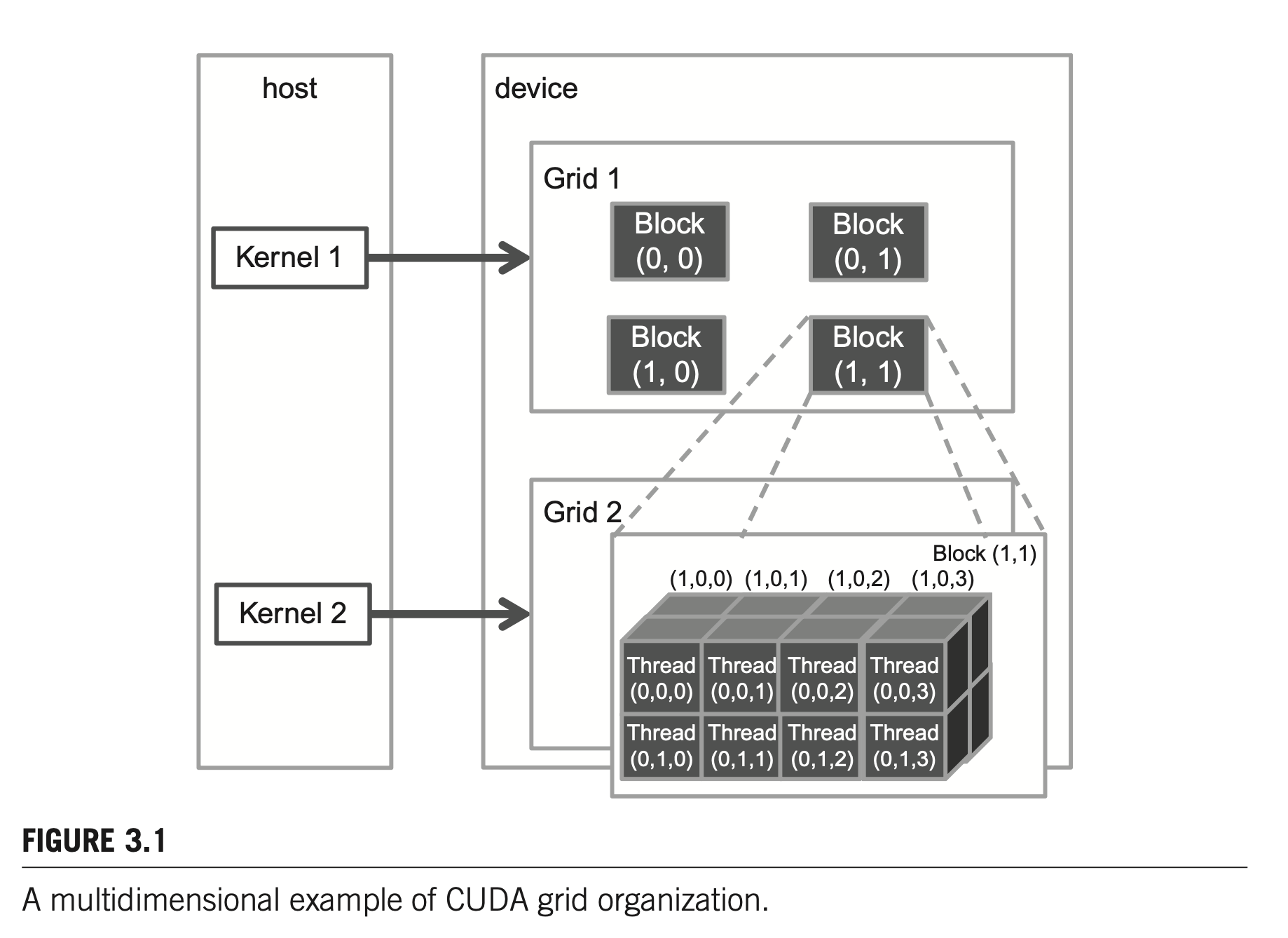
Mapping Threads to Multidimensional Data
The choice of 1D, 2D or 3D thread organizations is usually based on the nature of the data. For example, array operations are 1D, picture related are 2D.
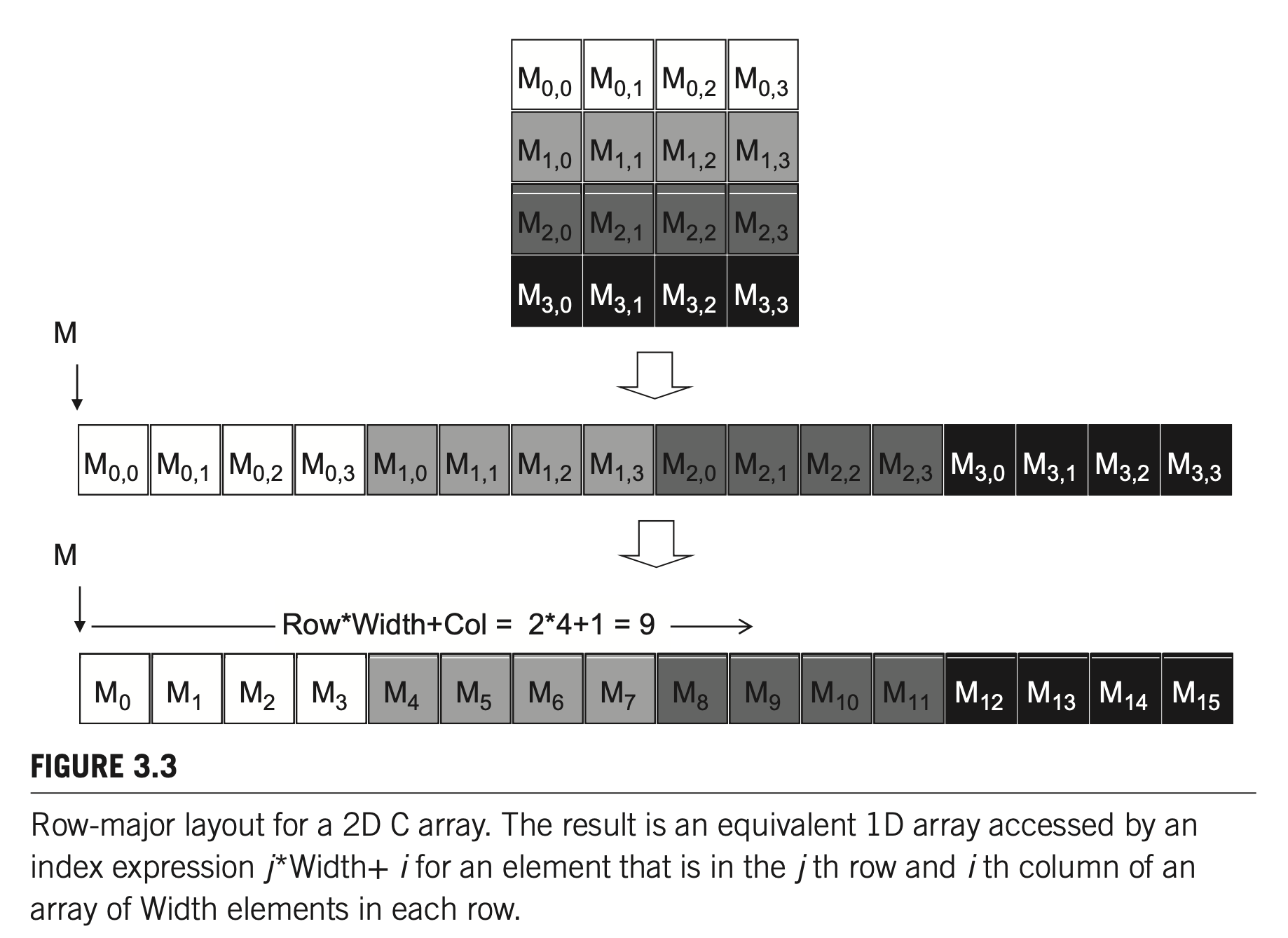
Although execution threads and statically allocated C arrays ca be multidimensional, in reality, all multidimensional arrays in C are linearized because of the use of a “flat” memory space in modern computers.
In dynamically allocated arrays, the CUDA C compiler leaves the work of such index translation to the programmer because of the lack of dimensional information at compile time.
A two-dimensional array can be linearized in at least two ways:
- row-major layout: place all elements of the same row into consecutive locations;
- column-major layout: place all elements of the same column into consecutive locations.
Multi-dimensional arrays in C are in row-major, while many math library like MKL or BLAS follow Fortran's column-major style, matrix transpose is required when calling these libraries from C.
Synchronization and Transparent Scalability
CUDA allows threads in the same block to coordinate their activities by using a barrier synchronization function __syncthreads() .
When a thread calls __syncthreads() , it will be held at the calling location until every thread in the block reaches the location.
The ability to synchronize also imposes execution constraints on threads within a block. A block can begin execution only when the runtime system has secured all resources needed for all threads in the block to complete execution. These threads should execute in close temporal proximity with each other to avoid excessively long waiting time.
CUDA only allows synchronization within a block, but not across different blocks and perform barrier synchronization with each other. This is an important tradeoff in CUDA design:
The CUDA runtime system can execute blocks in any order relative to each other because non-of them need to wait each other. A high-end system may execute a large number of blocks at one time while a low-cost system may only execute a small number of blocks.
The ability to execute the same application code on hardware with different numbers of execution resources is referred to as transparent scalability.
Query Device Properties
Code querying the number of devices and device properties:
int dev_cnt;
cudaGetDeviceCount(&dev_cnt);
printf("CUDA device count: %d\n", dev_cnt);
cudaDeviceProp dev_prop;
for (int i = 0; i < dev_cnt; ++i) {
cudaGetDeviceProperties(&dev_prop, i);
printf("\nGet device property for GPU %d:\n", i);
printf("Name: %s\n", dev_prop.name);
printf("Clock rate: %d\n", dev_prop.clockRate);
printf("Max Threads Per Block: %d\n", dev_prop.maxThreadsPerBlock);
printf("SM Count: %d\n", dev_prop.multiProcessorCount);
printf("Max Threads Dim(x, y, z): %d, %d, %d\n", dev_prop.maxThreadsDim[0], dev_prop.maxThreadsDim[1], dev_prop.maxThreadsDim[2]);
printf("Max Grid Size(x, y, z): %d, %d, %d\n", dev_prop.maxGridSize[0], dev_prop.maxGridSize[1], dev_prop.maxGridSize[2]);
}Execution output:
CUDA device count: 4
Get device property for GPU 0:
Name: NVIDIA A100-SXM4-40GB
Clock rate: 1410000
Max Threads Per Block: 1024
SM Count: 108
Max Threads Dim(x, y, z): 1024, 1024, 64
Max Grid Size(x, y, z): 2147483647, 65535, 65535
Get device property for GPU 1:
Name: NVIDIA A100-SXM4-40GB
Clock rate: 1410000
Max Threads Per Block: 1024
SM Count: 108
Max Threads Dim(x, y, z): 1024, 1024, 64
Max Grid Size(x, y, z): 2147483647, 65535, 65535
Get device property for GPU 2:
Name: NVIDIA A100-SXM4-40GB
Clock rate: 1410000
Max Threads Per Block: 1024
SM Count: 108
Max Threads Dim(x, y, z): 1024, 1024, 64
Max Grid Size(x, y, z): 2147483647, 65535, 65535
Get device property for GPU 3:
Name: NVIDIA A100-SXM4-40GB
Clock rate: 1410000
Max Threads Per Block: 1024
SM Count: 108
Max Threads Dim(x, y, z): 1024, 1024, 64
Max Grid Size(x, y, z): 2147483647, 65535, 65535Thread Scheduling and Latency Tolerance
In the majority of scheduling implementation to date, a block assigned to an SM is further divided into 32 thread units called warps.
The warp is the unit of thread scheduling in SMs. An SM is designed to execute all threads in a warp following the Single Instruction, Multiple Data (SIMD) model - i.e., at any instant in time, one instruction is fetched and executed for all threads in the warp.
When an instruction to be executed by a warp needs to wait for the result of a previously initiated long-latency operation, the warp is not selected for execution. If more than one warp is ready for execution, a priority mechanism is used to select one for execution. This mechanism of filling the latency time of operations with work from other threads is often called “latency tolerance” or “latency hiding”.
This ability to tolerance long-latency operation is the main reason GPUs do not dedicate nearly as much chip area to cache memories and branch prediction mechanisms as do CPUs.