TL;DR: Slingshot Interconnect
An In-Depth Analysis of the Slingshot Interconnect describes SLINGSHOT, an interconnection network for large scale computing systems, including its architecture and experiments on congestion control and QoS.
In this post I share my digests of this paper.
Introduction
HPL and HPCG are two commonly used benchmarks to assess supercomputing systems. HPCG is typically characterized by ~50x lower performance compared to HPL, partly due to the higher communication intensity of HPCG.
Moreover, many data center workloads are latency-sensitive, and tail-latency is much more relevant than the best case or average latency.
To address these issues, Cray designed the Slingshot interconnection network. It will power all three US announced exa-scale systems (all three are in production as of 2025) and numerous supercomputer.
Slingshot provides key features such as adaptive routing and congestion control, quality of service (QoS) to reduce tail latency and protect applications from interference or network noise. It also brings HPC features to Ethernet, such as low latency, low packet overhead, and optimized congestion control, while maintaining industry standards.
Slingshot Architecture
Switch Technology - ROSETTA
The core of the Slingshot is the ROSETTA switch, providing 64 ports at 200Gbps per direction.
Each port uses four lanes of 56 Gb/s Serializer/Deserializer (SerDes) blocks using Pulse-Amplitude Modulation (PAM-4) modulation. Due to Forward Error Correction (FEC) overhead, 50Gb/s can be pushed through each lane. The ROSETTA ASIC consumes up to 250 Watts and is implemented on TSMCs 16 nm process. ROSETTA is composed by 32 peripheral function blocks and 32 tile blocks. The peripheral blocks implement the SerDes, Medium Access Control (MAC), Physical Coding Sublayer (PCS), Link Layer Reliability (LLR), and Ethernet lookup functions.
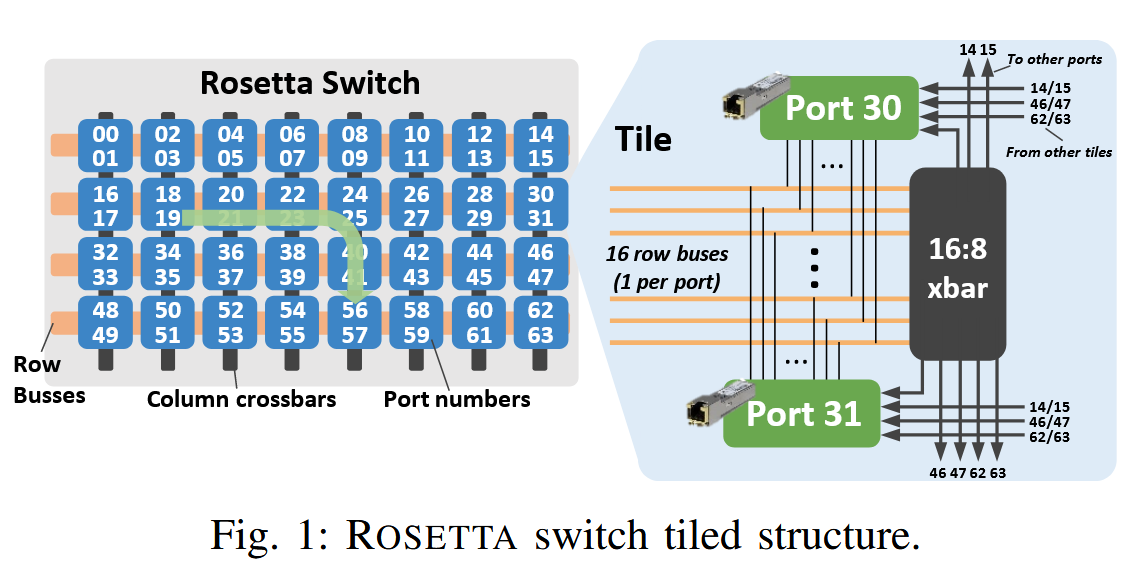
The 32 tile blocks implement the crossbar switching between the 64 ports, but also adaptive routing and congestion management functionalities. The tiles are arranged in four rows of eight tiles, with two switch ports handled per tile. The tiles on the same row are connected through 16 per-row buses, whereas the tiles on the same column are connected through dedicated channels with pertile crossbars. Each row bus is used to send data from the corresponding port to the other 16 ports on the row. The pertile crossbar has 16 inputs (i.e., from the 16 ports on the row) and 8 outputs (i.e., to the 8 ports on the column). For each port, a multiplexer is used to select one of the four inputs (this is not explicitly shown in the figure for the sake of clarity). Packets are routed to the destination tile through two hops maximum.
Topology
Rosetta switches can be arranged into any arbitrary topology. Dragonfly is the default topology for Slingshot-based systems.
Dragonfly is a hierarchical direct topology, where all the switches are connected to both computing nodes and other switches. Sets of switches are connected between each other forming so-called groups. The switches inside each group may be connected by using an arbitrary topology, and groups are connected in a fully connected graph.
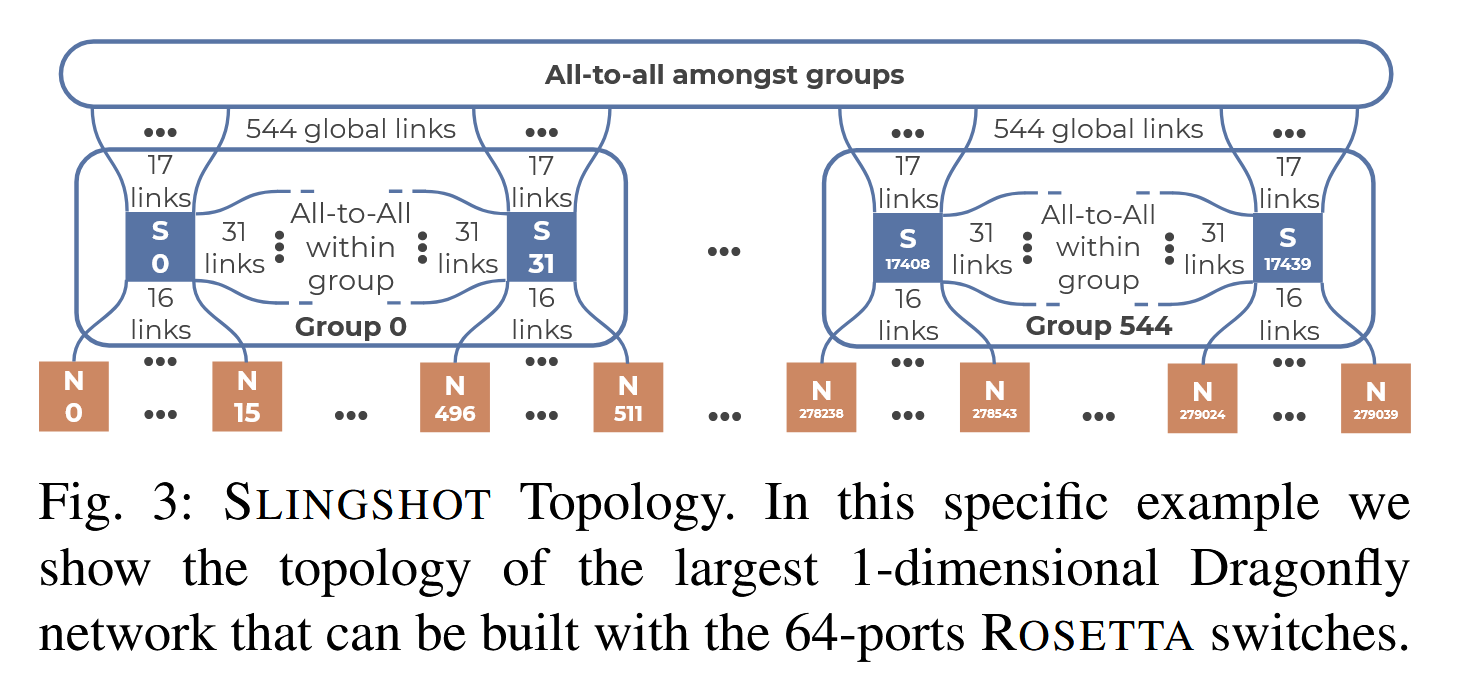
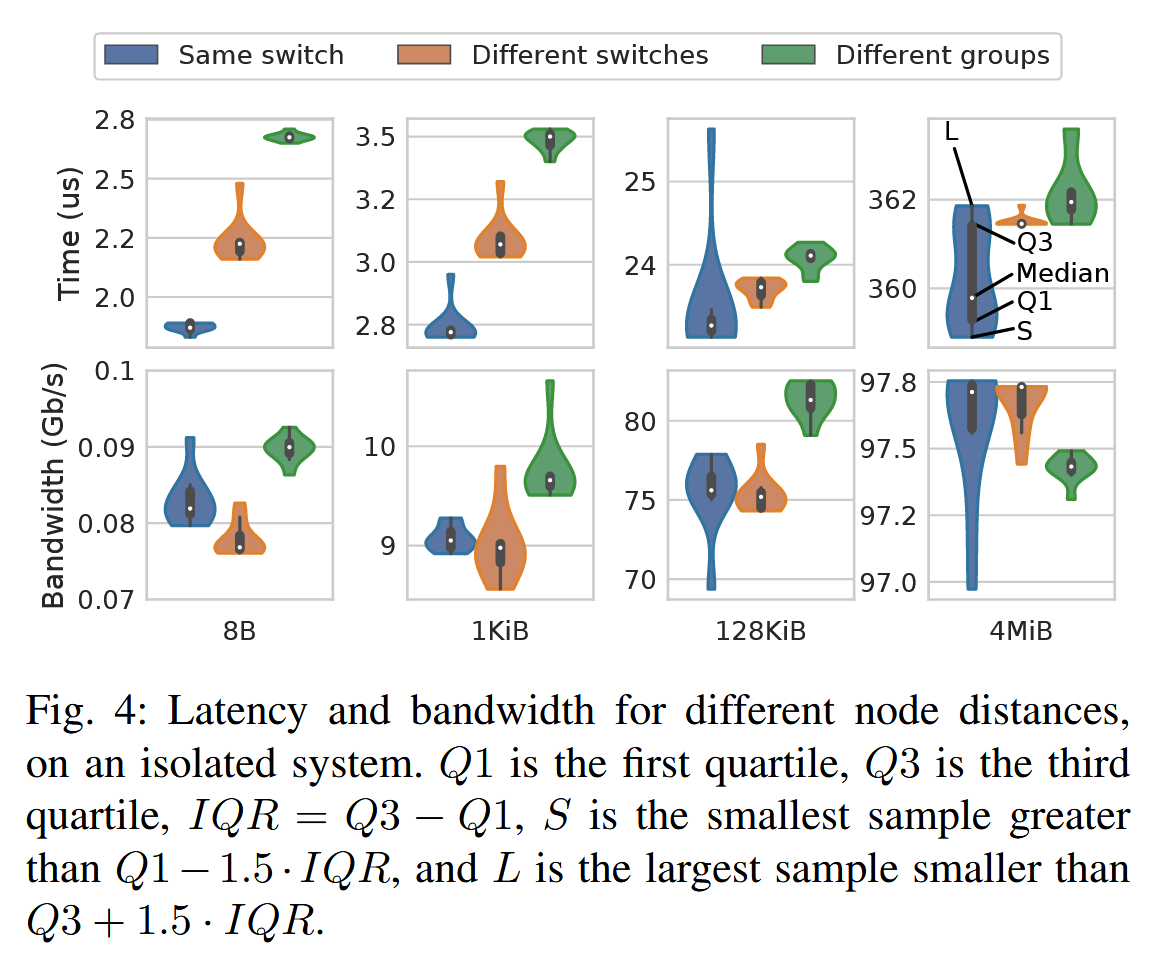
Due to the full-connectivity both within the group and between groups, this topology has a diameter of 3 switch-to-switch hops. Thanks to the low diameter, applications performance only marginally depend on the specific node allocation and distance:
- connected to ports on the same switch (1 inter-switch hop)
- connected to two different switches in the same group (2 inter-switch hops)
- connected to two different switches in two different groups (3 inter-switch hops)
Routing
In Dragonfly networks (including Slingshot), any pair of nodes is connected by multiple minimal and non-minimal paths.
Sending data on minimal paths is clearly the best choice on a quiet network. However, in a congested network, with multiple active jobs, those paths may be slower than longer but less congested ones.
To provide the highest throughput and lowest latency, Slingshot implements adaptive routing: before sending a packet, the source switch estimates the load of up to four minimal and non-minimal paths and sends the packet on the best path, that is selected by considering both the paths’ congestion and length.
Congestion Control
Two types of congestion might affect an interconnection network: endpoint congestion, and intermediate congestion. The endpoint congestion mostly occurs on the last-hop switches, whereas intermediate congestion is spread across the network.
Adaptive routing improves network utilization and application performance by changing the path of the packets to avoid intermediate congestion. However, even if adaptive routing can bypass congested intermediate switches, all the paths between two nodes are affected in the same way by endpoint congestion.
To mitigate this problem, Slingshot introduces a sophisticated congestion control algorithm, entirely implemented in hardware, that tracks every in-flight packet between every pair of endpoints in the system. Slingshot can distinguish between jobs that are victims of congestion and those who are contributing to congestion, applying stiff and fast backpressure to the sources that are contributing to congestion. By tracking all the endpoints pairs individually, Slingshot only throttles those streams of packets who are contributing to the endpoint congestion, without negatively affecting other jobs or other streams of packets within the same job who are not contributing to congestion.
Quality of Service (QoS)
Whereas congestion control partially protects jobs from mutual interference, jobs can still interfere with each other. To provide complete isolation, in Slingshot jobs can be assigned to different traffic classes, with guaranteed quality of service.
QoS and congestion control are orthogonal concepts. Indeed, because traffic classes are expensive resources requiring large amounts of switch buffers space, each traffic class is typically shared among several applications, and congestion control still needs to be applied within a traffic class.
Each traffic class is highly tunable and can be customized by the system administrator in terms of priority, packets ordering required, minimum bandwidth guarantees, maximum bandwidth constraint, lossiness, and routing bias.
For example, it may assign latency sensitive collective operations such as MPI_Barrier and MPI_Allreduce to high-priority and low-bandwidth traffic classes, and bulk point-to-point operations to higher bandwidth and lower priority classes.
Ethernet Enhancement
To improve interoperability, and to better suit datacenters scenarios, Slingshot is fully Ethernet compatible, and can seamlessly be connected to third-party Ethernet-based devices and networks.
Slingshot provides additional features on top of standard Ethernet, improving its performance and making it more suitable for HPC workloads. Slingshot uses this enhanced protocol for internal traffic, but it can mix it with standard Ethernet traffic on all ports at packet-level granularity.
Software Stack
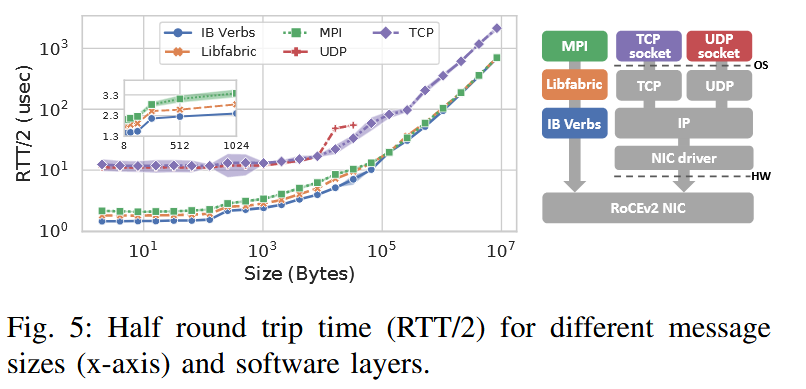
Communication libraries can either use the standard TCP/IP stack or, in case of high-performance communication libraries such as MPI, Chapel, and SHMEM, the libfabric interface.
Cray MPI is derived from MPICH and implements the MPI-3.1 standard. Proprietary optimizations and other enhancements have been added to Cray MPI targeted specifically for the Slingshot hardware.
Any MPI implementation supporting libfabric can be used out of the box on SLINGSHOT. Moreover, standard API for some features, like traffic classes, have been recently added to libfabric and could be exploited as well.
Performance Study
The performance study is focused on congestion control and quality of service management, on the following system: Crystal: a system based on Cray Aries interconnect, with 698 nodes; Malbec: a system based on Slingshot interconnect, with 484 nodes in 4 groups, each at most 128 nodes; Shandy: s system based on Slingshot interconnect, with 1024 nodes in 8 groups, each containing 128 nodes.
Congestion Control
Nodes in the system are divided in two partitions: victim nodes and aggressor nodes. The aggressor nodes generate congestions that impacts the performance of victim nodes.
Three factors are considered for their impact on the system:
- Victim/aggressor ratio
- Victim/aggressor allocation
- Message size
To report congestion, mean congestion impact $C$ is defined as $C = \cfrac{T_c}{T_i}$ where $T_i$ is the mean execution time of the victim when execution in isolation and $T_c$ is the mean execution time of the victim when co-executed with the aggressor.
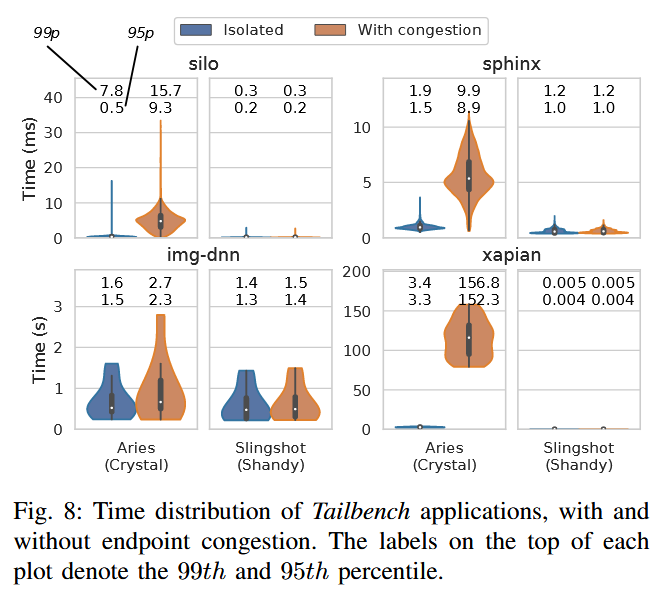
Tailbench is a benchmark for latency-sensitive datacenter applications, covering a wide range of latencies, from microseconds to seconds.

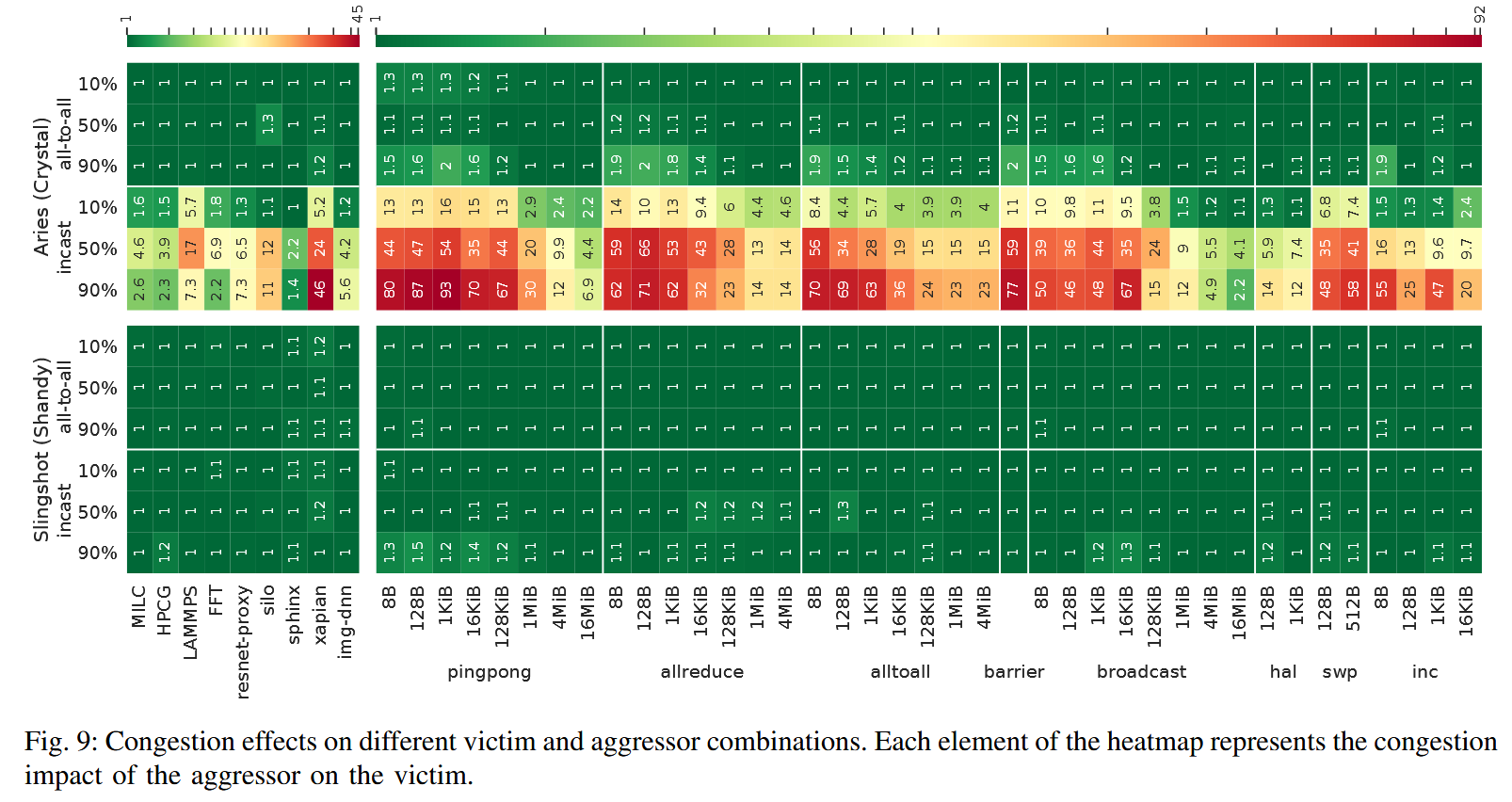
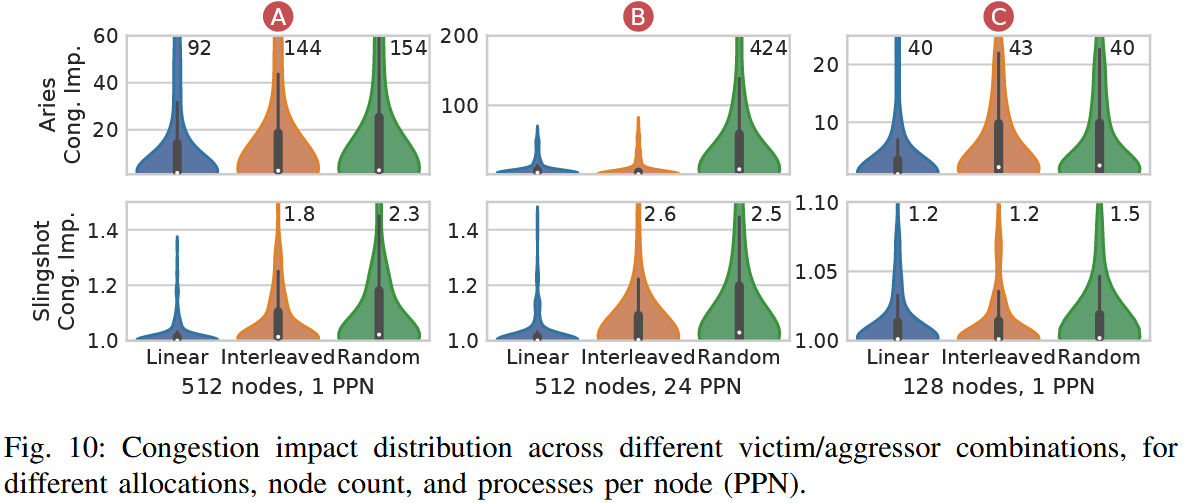
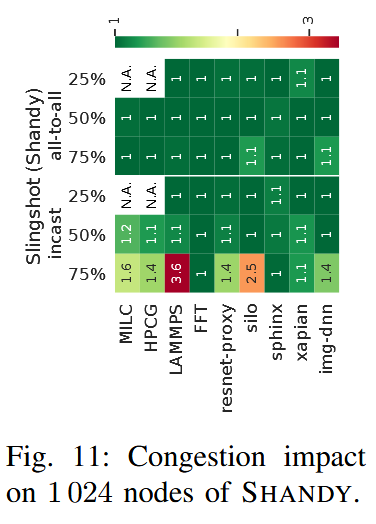
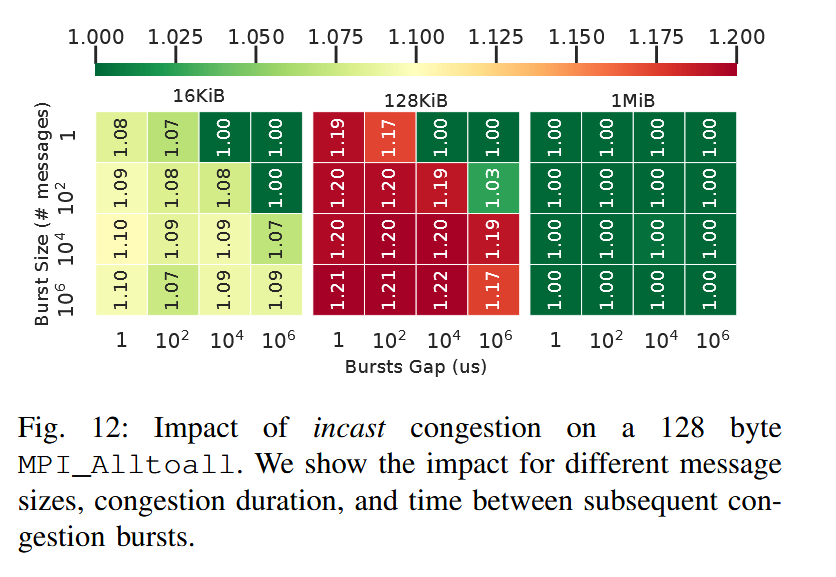
Traffic Classes
It is worth remarking that traffic classes and congestion control are orthogonal concepts. Traffic classes can be used to protect a job (or parts of it) from other traffic, and they can allocate resources fairly or unfairly between users and jobs. However, even if resources are assigned fairly, congestion can still occur due to jobs filling up the buffers. Congestion control is used to avoid such situations within and across traffic classes.
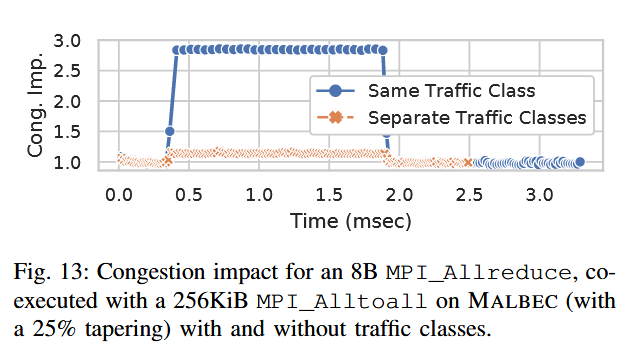
State of the Art
Interconnection Networks
InfiniBand is an open standard for high-performance network communications. Different vendors manufacture InfiniBand switches and interfaces, and the InfiniBand standard is not tied to any specific network topology. The most commonly used InfiniBand implementations rely on Mellanox hardware, with switches arranged in a fat tree topology.
Cray ARIES is the 7th generation of Cray interconnection networks, based on a Dragonfly topology and supports different systems configuration.
Tofu Interconnect D (TofuD) is the third generation Tofu interconnection networks used by the Fugaku supercomputer. TofuD provides a peak injection rate of 300Gb/s per node and, like its predecessors, it is based on a 6D mesh/torus. Around 25% of the links used by the interconnect are optical. To reduce latency and improve fault resiliency, TofuD uses a technique called dynamic packet slicing, to split the packets in the data-link layer. This can either be used to split the packet and improve the transmission performance or to duplicate the packet to provide fault tolerance in case the link quality degrades. Moreover, this interconnect provides an offload engine, called Tofu Barrier, to execute collective operations without involving the CPU.
Dragonfly+ is a variation of the Dragonfly interconnect, where the switches inside a group are connected through a fat-tree network.
Interconnection Networks Benchmarks
The GPCNet benchmark has been recently proposed as a portable benchmark for estimating network congestion. The main goal of GPCNet was to design a portable congestion benchmarking infrastructure by using a small set of victim microbenchmarks (random ring and MPI_Allreduce) to easily compare different systems. However, this does not represent a wide spectrum of real scenarios.
Moreover, the GPCNet paper only analyzes the impact of congestion for a fixed victim message size, allocation, and aggressor/victim ratio. However, as discussed in this paper, all these factors play a role in the observed congestion and they can be helpful to understand the system performance
Reference
Daniele De Sensi, Salvatore Di Girolamo, Kim H. McMahon, Duncan Roweth, and Torsten Hoefler. 2020. An in-depth analysis of the slingshot interconnect. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC ‘20). IEEE Press, Article 35, 1–14.