Running NVIDIA and AMD GPUs in a Single K3S Cluster
Modern AI and HPC workloads often require different types of accelerators depending on the specific use case. Running a heterogeneous GPU cluster allows maximizing resource utilization and choosing the optimal hardware for each job, while sharing authentications, storage, gateway...
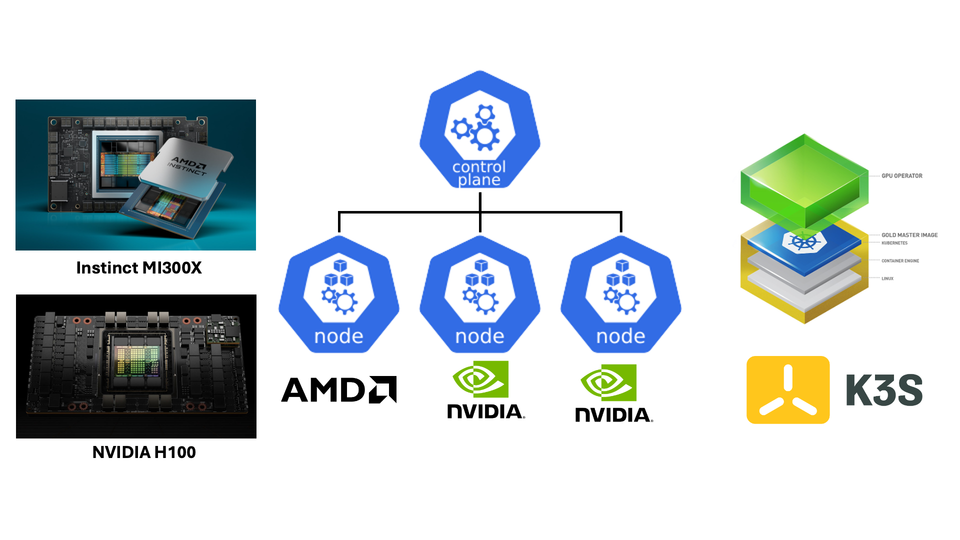
In this post, we'll set up a K3S cluster that can orchestrate both NVIDIA H100 and AMD MI300X GPUs, allowing workloads to specifically request the accelerator type they need.
Cluster Architecture
- k8s-ctl: control plane node with etcd (no GPU)
- k8s-amd1: worker node with AMD MI300X GPUs
- k8s-nv1 & k8s-nv2: worker nodes with NVIDIA H100 GPUs
Understanding Device Plugins and Operators
Kubernetes doesn't natively understand specialized hardware like GPUs. Device Plugins solve this by:
- Advertising hardware resources to the kubelet
- Performing device-specific operations during pod creation
- Managing device allocation and health monitoring
Device plugins typically run as DaemonSets - a Kubernetes workload type that ensure exactly one pod run on each node (or selected nodes), this makes perfect sense for device plugins since they need to:
- Run on each node with the target hardware
- Register with local kubelet and continuously monitor local device
- Survive node reboots and cluster changes
Operators extend this concept by providing higher-level management of these device plugins, handling installation, configuration, and lifecycle management through Custom Resource Definitions (CRDs).
AMD and NVIDIA have both Device Plugin and Operator. Device plugins registers GPU resources with kubelet, handles GPU allocations to pods and provides basic health check. Operators are higher-level comprehensive orchestration tools that include device plugins but also have other tools for monitoring, labeling etc..
AMD Device Plugin | AMD GPU Operator
NVIDIA Device Plugin | NVIDIA GPU Operator
In this post, we only install lightweight device plugin to manage GPU but not the full operator framework.
Prerequisite
Before diving into Kubernetes configuration, ensure each node has the appropriate drivers and container runtime support.
NVIDIA Node Setup
For nodes with NVIDIA GPU, NVIDIA GPU driver and NVIDIA container toolkit are required. In addition, NVIDIA container runtime needs to be configured as the default low-level runtime.
To change the default container runtime of K3S to NVIDIA container runtime:
mkdir -p /etc/rancher/k3s
echo 'default-runtime: nvidia' >> /etc/rancher/k3s/config.yaml
systemctl restart k3s-agent.serviceK3S Alternative Container Runtime Support
AMD Node Setup
For nodes with AMD GPU, AMD GPU driver and ROCm are required. No container runtime need to be configured.
Deploy Device Plugins
Label Nodes
Since AMD and NVIDIA device plugins require their respective drivers and libraries and cannot run on nodes without dependencies, we create a label accelerator to distinguish AMD and NVIDIA GPU nodes.
kubectl label node k8s-ctl accelerator=none
kubectl label node k8s-nv1 accelerator=nvidia
kubectl label node k8s-nv2 accelerator=nvidia
kubectl label node k8s-amd1 accelerator=amdDeploy NVIDIA Device Plugin
Download the device plugin manifest:
wget https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.1/deployments/static/nvidia-device-plugin.ymlEdit manifest to add nodeSelector to select only nodes with accelerator=nvidia label:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
name: nvidia-device-plugin-ds
spec:
runtimeClassName: nvidia
nodeSelector:
accelerator: nvidia
...Apply and wait until the daemon set is available.
AMD Device Plugin
Similarly, download the AMD device plugin manifest and edit nodeSelector
wget https://raw.githubusercontent.com/ROCm/k8s-device-plugin/master/k8s-ds-amdgpu-dp.yamlapiVersion: apps/v1
kind: DaemonSet
metadata:
name: amdgpu-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: amdgpu-dp-ds
template:
metadata:
labels:
name: amdgpu-dp-ds
spec:
nodeSelector:
accelerator: amd
...Apply and wait until the daemon set is available.
kubectl get daemonsets -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
amdgpu-device-plugin-daemonset 1 1 1 1 1 accelerator=amd 5d
nvidia-device-plugin-daemonset 2 2 2 2 2 accelerator=nvidia 5dQuery Device Resource
GPU devices will be shown as a resource similar to CPU and GPU.
kubectl describe node k8s-amd | grep Capacity -A 10
--
Capacity:
cpu: 192
amd.com/gpu: 8
pods: 110
...kubectl describe node k8s-nv1 | grep Capacity -A 10
--
Capacity:
cpu: 192
nvidia.com/gpu: 8
pods: 110
...kubectl get nodes -o custom-columns=NAME:.metadata.name,"AMD GPU":"status.capacity.amd\.com/gpu","NVIDIA GPU":"status.capacity.nvidia\.com/gpu"
NAME AMD GPU NVIDIA GPU
k8s-ctl <none> <none>
k8s-amd1 8 <none>
k8s-nv1 <none> 8
k8s-nv2 <none> 8Requesting GPU Resources in Workloads
Requesting GPU resources is similar to requesting other resources, as declare in the manifest file:
apiVersion: apps/v1
kind: Deployment
metadata:
...
spec:
template:
spec:
name: ...
image: ...
resources:
limits:
amd.com/gpu: "1"
requests:
amd.com/gpu: "1"A sample GPU job may be:
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda12.5.0
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
EOFkubectl logs gpu-pod
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
DoneMore Kubernetes posts on my Kubernetes index page.



